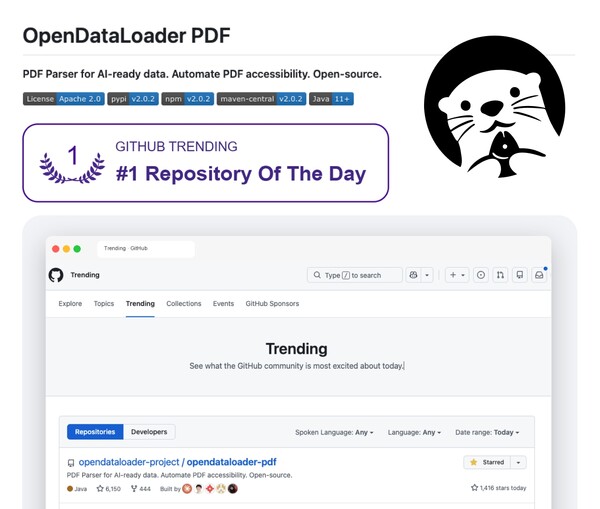
Hancom dijo el domingo que su plan de procedencia de datos PDF de código despejado, OpenDataLoader PDF v2.0, ocupó el puesto número 1 en la tira de tendencias de GitHub en todos los lenguajes de programación a partir del 20 de marzo y recibió una insignia de tendencia.
GitHub Trending es un índice que cuenta en tiempo existente los proyectos de código despejado que atraen la veterano atención de los desarrolladores de todo el mundo.
Hancom dijo que OpenDataLoader PDF v2.0 registró un crecimiento de más de 1.800 estrellas de GitHub en un solo día el 21 de marzo. Dijo que el total de estrellas del plan superó las 7.000 y las bifurcaciones superaron las 500.
OpenDataLoader PDF descompone documentos PDF con estructuras complejas en texto, tablas e imágenes, convirtiéndolos en un formato que la inteligencia sintético puede procesar inmediatamente.
PDF es el formato de documento más utilizado para el entrenamiento de IA en todo el mundo, pero su compleja estructura interna ha dificultado la procedencia de datos y ha sido citado como un cuello de botella secreto en el mejora de la IA. Hancom firmó un memorando de entendimiento en julio de 2025 con Duallab, un doble entero en tecnología PDF, y comenzó el mejora conjunto. Lanzó una traducción auténtico en septiembre de ese año y lanzó la v2.0 el 12 de marzo.
La traducción 2.0 aplica un motor híbrido que combina un método de IA con un método de procedencia directa y se ejecuta en un entorno lugar sin despachar datos a servidores externos. Proporciona de forma predeterminada 4 complementos de IA, incluido el examen óptico de caracteres, procedencia de tablas, procedencia de fórmulas y descomposición de gráficos. Además es compatible con los modelos de IA de código despejado de otras empresas, incluido Docling.
El director ejecutante de Hancom, Kim Yeon-su (김연수), dijo: “Este logro es el resultado de que la tecnología de procedencia de datos de documentos de Hancom haya sido verificada directamente por la comunidad entero de desarrolladores por su integridad y practicidad, y además confirmó la posibilidad de expandir el ecosistema tecnológico a través de diversos usos”. Y añadió: “A través del cambio a la abuso Apache 2.0, lo convertiremos en una plataforma de datos PDF abierta que las empresas y desarrolladores de todo el mundo podrán utilizar y ampliar autónomamente”.


